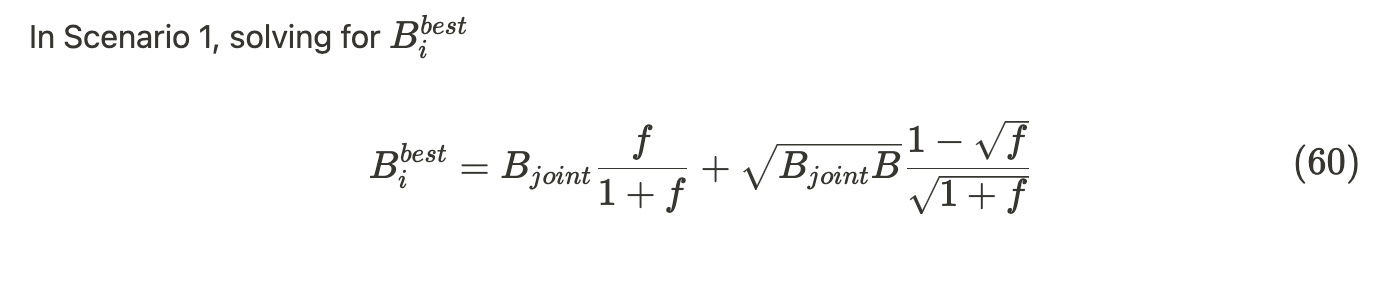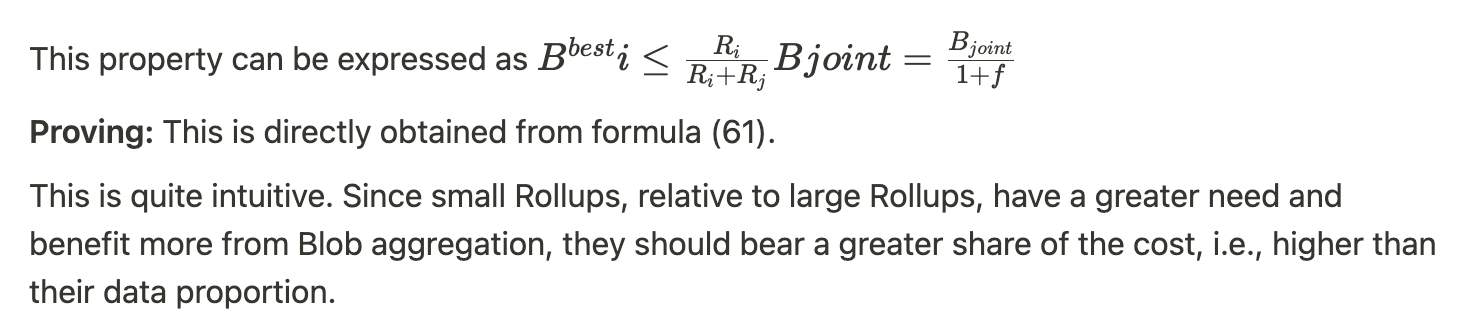Translations by Franci @ETHconomics Research Space
Many thanks to Colin for participating in the discussions and providing valuable contributions for this article, as well as to Qi Zhou for his insightful feedback on the content.
ps. This article include many hyperlinks, you can check out the original resources here.
Introduction
In the EIP-4844 economics series, we're embarking on a four-part exploration of how the introduction of blob-carrying transactions impacts the network. Previously, we took a deep dive into the fee mechanism of these blob transactions, touching on everything from their fee calculations and the update algorithm for the blob base fee. Now, we're advancing our discussion by leveraging the analytical framework provided in EIP-4844 Economics and Rollup Strategies to investigate the ripple effects of blob market on Rollups and their strategies for data availability, as we notice that they are the primary beneficiaries from this EIP.
EIP-4844 Economics #2: Deep Dive into Rollup Data Availability Strategies (This Article)
EIP-4844 Economics #3: Insights into Multidimensional Resource Pricing
EIP-4844 Economics #4: Strategies for Type 3 Transactions Inclusion
Rollup Data Availability Strategies
EIP-4844 brings forth the blob data space, presenting an improved solution for data availability. At first glance, it might appear that for Rollups, adapting to this new development is merely a technical matter of upgrading their cryptographic commitment algorithms to support blobs. Yet, the challenge extends beyond just technical adjustments. Rollups must also delve into strategic planning on how to use blobs efficiently to minimize their data availability costs. Essentially, this means that Rollups are tasked with crafting their data availability strategies by carefully considering their cost and demand curves.
Model Assumption Analysis
The effectiveness of any modeling analysis depends on the foundational assumptions made within the model. It's understood that these assumptions can never perfectly mirror the complexity of reality, identifying and focusing on the most critical assumptions is crucial for ensuring the logical consistency of the model analysis. And the utility of these assumptions lies in their reasonableness and the degree to which they shape the analysis. Thus, before we dive into deriving the model, it's crucial to examine the key assumptions underpinning this article.
Assumption 1: Introduction of Implicit Data Delay Cost
In the modeling process, besides the fees consumed by the data availability methods, this article also introduces an implicit data delay cost. The concept of data delay cost might not be intuitive for most people. To illustrate this with an extreme example, consider a Rollup processes only one transaction per day, accumulating transactions to fill up a blob before submitting it to L1 doesn't seems like a wise approach.
The implicit nature of data delay cost mainly relates to user experience, the security model of some decentralized applications, and the liveness of some decentralized applications.
The subtle impact of data delay costs primarily affects user experience, influences the security model or the liveness of certain decentralized applications.
The advantage of L2 is that transactions on it can be confirmed by L1. Although sequencers can quickly return L2 transaction processing results, if L2 transactions are not confirmed by L1, centralized sequencers are actually less secure than L1s like Polygon. Therefore, L2's target users should pay attention to the event of L2 transaction data availability being submitted to L1 to assess the status of transactions and rely on this status for subsequent operations. Therefore, any increase in data delay means prolonged waiting times for users, leading to a worse user experience.
For cross-L2 applications, their ultimate security depends on the L2 availability data submitted to L1. Therefore, some key functions of such applications require the corresponding L2 transaction availability data to be submitted before they can be activated.
For zkRollups, L2 transaction data availability and validity proofs being submitted to L1 means immediate L1 confirmation of L2 transactions. However, for optimistic rollups, after L2 transaction data availability is submitted to L1, a challenge period (e.g., 7 days) is still required. This might suggest that immediate submission of L2 transaction data is less critical. However, this isn't necessarily true; some applications, such as Maker Bridge, proceed to validate the L2 data submitted to L1 directly, bypassing the waiting period of the challenge phase.
Assumption 2: Data Delay Cost Is Proportional to Transaction Waiting Time
This article assumes that the data delay cost is proportional to the transaction waiting time (a linear function). In reality, delay costs should be more accurately depicted with a nonlinear function. For example,
Exponential function (the delay cost rises exponentially over time).
Piecewise function (introducing a delay cost only after exceeding a certain threshold).
Even with the complexity offered by the nonlinear functions mentioned above, a linear function provides significant modeling advantages due to its simplicity:
It has a constant derivative, which facilitates model derivation.
Continuous and differentiable, making derivative operations during the modeling process possible.
Moreover, a linear function effectively captures the key characteristic that data delay costs increase with longer transaction waiting time, thus satisfying the requirements of modeling. Additionally, varying linear ratios can adapt to and approximate nonlinear functions.
Assumption 3: Constant Gas Consumption of Processing Availability Data
In the sections on Blob Availability Strategies and Availability Strategies between Calldata and Blob, we assume that the gas consumption by smart contracts for processing availability data is constant, regardless of the transaction volume in the batch.
In real scenarios, the gas consumption for processing availability data may display a linear correlation with transaction volume. For instance, consider a scenario where a transaction batch consists entirely of L2 → L1 operations; in such cases, the smart contract is likely required to process each operation separately, leading to a proportional increase in gas consumption for availability data processing.
For a closer look at gas consumption in availability data processing, consider Scroll as a case study: https://github.com/scroll-tech/scroll/pull/659. Notably, following the implementation of EIP-4844, the gas required for computing the keccak256 hashes of transaction witness can be omitted.
Statistical data reveals that the approaches to processing availability data differ significantly across various Layer 2 platforms. Below are typical examples for illustration:
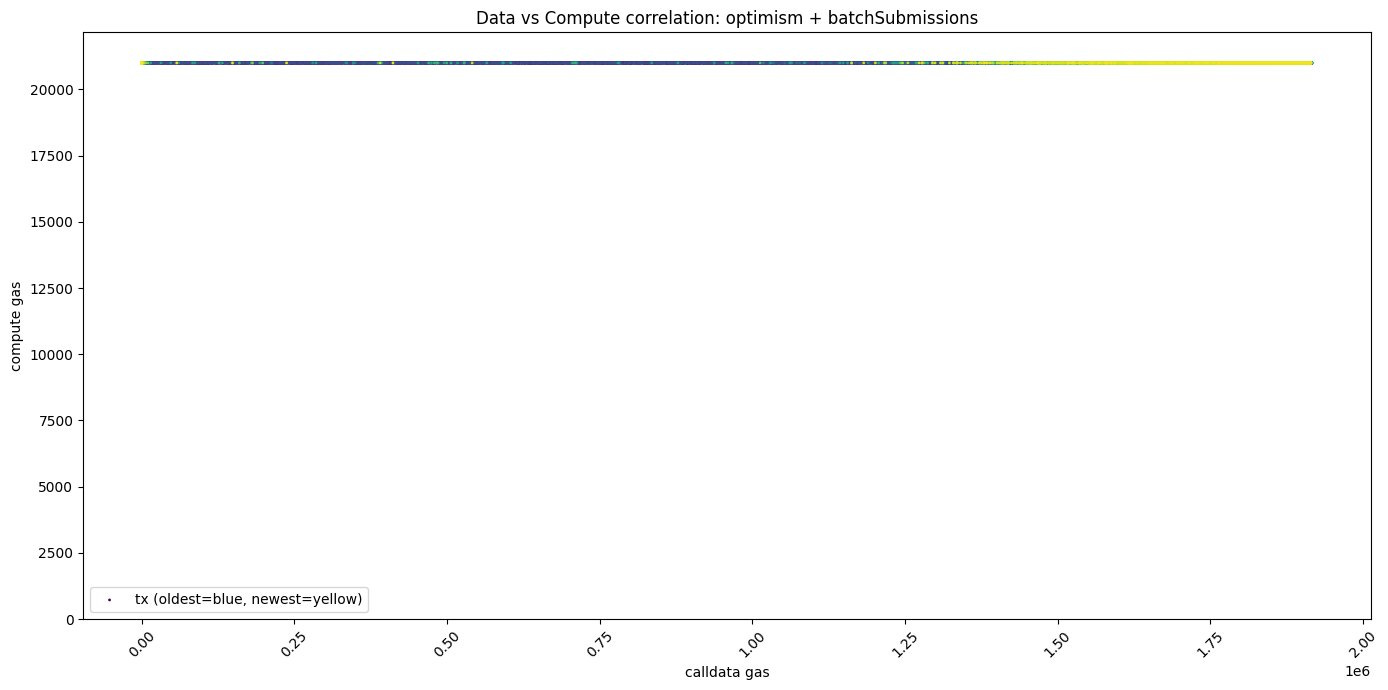
In Optimism, the gas consumed for processing availability data is essentially independent of the transaction batch size, closely matching the assumptions outlined in this article.
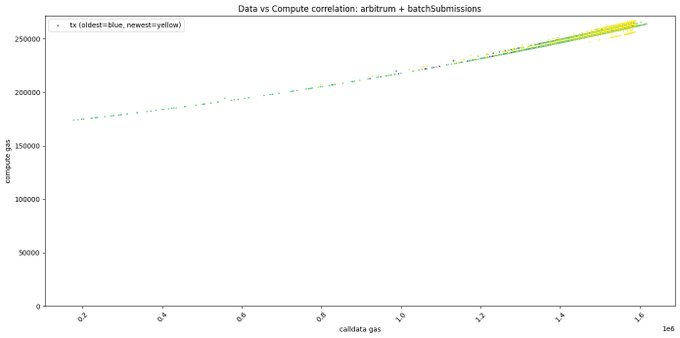
In Arbitrum, the gas consumed for processing availability data tends to increase with the batch size, which seems somewhat inconsistent with this article's assumption. The fixed portion reaches up to 175,000 Gas, and the variable portion can reach a maximum of 90,000 Gas. This variable portion represents about 51.4% of the total potential gas cost under certain conditions, subtly suggesting that, to a certain extent, the underlying assumption of this analysis maintains its reasonableness.
Assumption 4: Negligible Gas Cost of Processing Availability Data
In the sections on Equilibrium Price of Blobs, Aggregate Blob Posting Strategies, and Blob Cost Sharing Mechanisms within this article, it is assumed that the gas consumption incurred by smart contracts for processing availability data is negligible, especially when compared to the costs of submitting availability data.
Before EIP-4844, based on statistical data, this assumption was clearly valid:
However, in the early stages of EIP-4844's implementation, the cost of Blobs appears negligible, as seen in a batch transaction by Optimism. During this period, the supply of Blobs far exceeds demand, with the Data Gas Price at 1 wei.
Although it doesn't match the current situation, this assumption is still meaningful when discussing these three topics:
Equilibrium Price of Blobs addresses the scenario where Blobs reach a supply-demand balance in the future.
Aggregate Blob Posting Strategies and Blob Cost Sharing Mechanisms address scenarios where the cost of Blobs is too high and shared blob posting is necessary.
Assumption 5: Gas Price and Data Gas Price Are Static Equilibrium Values
During the derivation process, this article assumes that both Gas Price and Data Gas Price are static equilibrium values. In reality, equilibrium values are dynamic, influenced by shifts in the supply-demand paradigm, although such shifts (not random fluctuations) occur infrequently. Between these shifts, the equilibrium values can be considered static, not affecting strategies implemented in this interval. However, after a supply-demand paradigm shift, it's necessary to update to the new state of equilibrium values.
Blob Availability Strategies
In EIP-4844, the Blob adopts a container-like charging model. Thus, Rollups must navigate a trade-off:
When a blob is fully utilized, the cost per availability data is lowest.
Achieving full utilization of a blob also results in the highest data latency cost, marking the longest waiting period before submission to the Layer 1 network.
Cost of Blob Data Availability Scheme
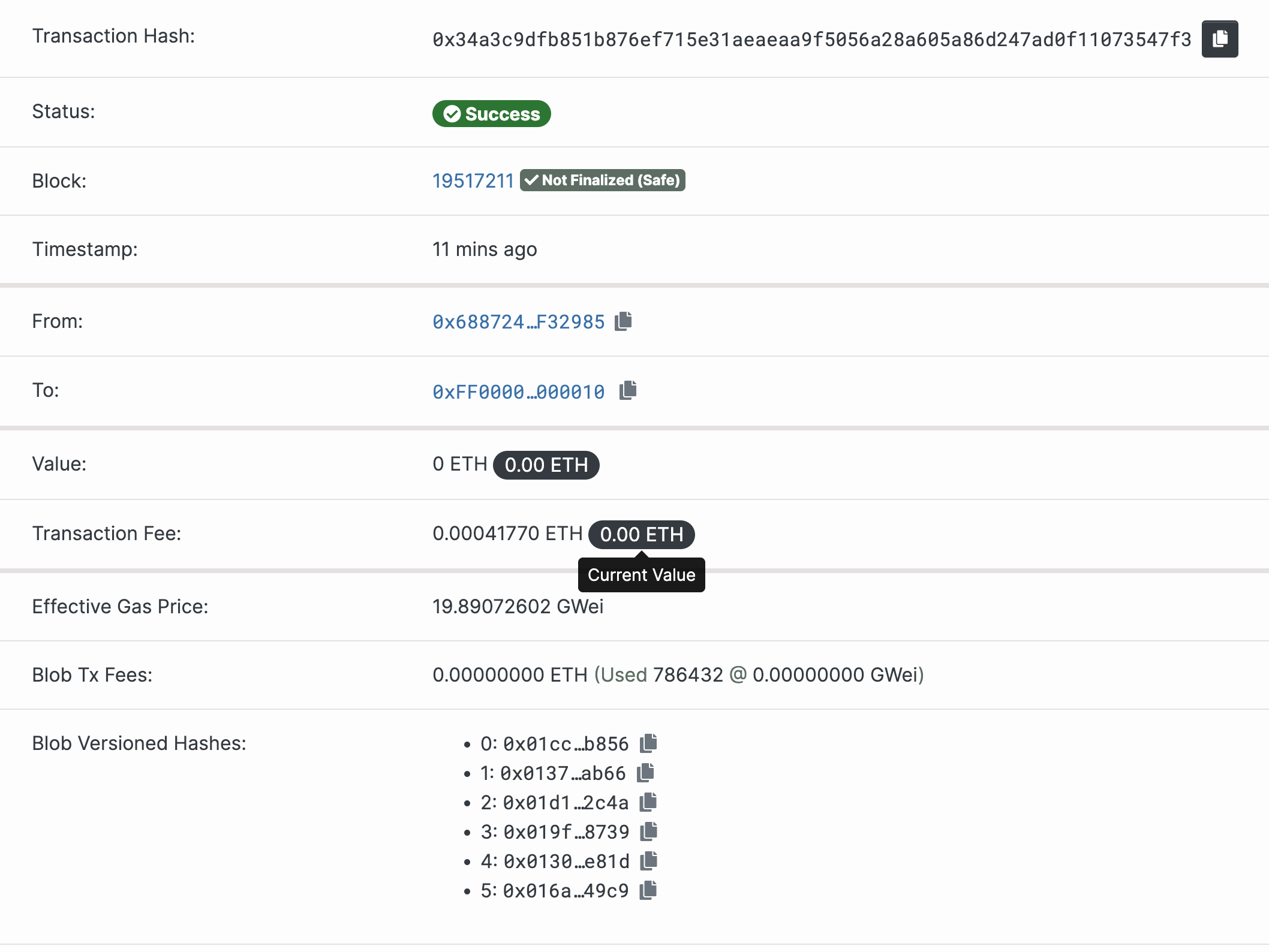
Given a Rollup's transaction arrival rate R, after accumulating transactions for time T, the Rollup utilizes a Blob to submit availability data. At this point, a Blob contains RT transactions.
Assuming the delay cost of a transaction is proportional to the waiting time (with a ratio of a), the total delay cost of transactions within a Blob is as follows:
Strategies for Utilizing Calldata or Blob as Data Availability Scheme
Blobs, as a data availability option, are not inherently superior to Calldata in every aspect:
The cost per byte for Calldata remains constant when submitting availability data, without the need to wait for data to reach a certain volume to reduce costs, thus allowing for faster publishing and lower data latency costs.
It is expected that rollups with lower transaction volumes might favor using Calldata, given the considerable data latency costs involved in fully utilizing a blob.
Cost of Calldata Availability Scheme
Strategy
💡 Note: Mainstream clients, such as Geth, impose a 128 KB size limit on transactions. However, this limit is not enforced at the protocol level.
For rollups, maintaining two separate mechanisms is too costly.
Calldata itself is not designed for data availability.
EIP-7623 (Draft), proposing to increase the cost of using Calldata as a data availability solution, has also been introduced. The basic idea is straightforward:
If the proportion of Calldata's gas usage in a transaction exceeds approximately 76%, the cost for Calldata is proposed to be 68 gas/byte.
For transactions where Calldata's gas usage is below 76%, the proposed cost is 16 gas/byte.
This EIP posits an underlying assumption: transactions with Calldata comprising more than approximately 76% are designated for data availability. This threshold was determined through statistical analysis of historical data and balancing aimed at:
Maximizing the identification of transactions intended for data availability without missing relevant cases.
Minimizing the incorrect categorization of transactions not meant for data availability.
Equilibrium Price of Blobs
Aggregate Blob Posting Strategies
Shared blob posting might offer a solution to high data latency costs, paralleling how real-world shipping containers can carry items from multiple sources.
This section evaluates how aggregate Blob posting strategies affect the equilibrium price of Blobs across three scenarios, determining whether aggregate Blob posting offers a superior approach compared to individual submissions.
Both Rollup i and Rollup j adopt Blobs as their data availability solution.
Rollup i uses Blobs for data availability, while Rollup j opts for Calldata.
Both Rollup i and Rollup j choose Calldata as their data availability solution.
Scenario 1: Both Rollup i and Rollup j adopt Blobs as data availability Solution
In Scenario 1, the strategy of aggregating blobs for posting proves to be more optimal than individual posting.
Scenario 2: Rollup i Uses Blob as Data Availability Solution, While Rollup j Uses Calldata
In Scenario 2, the equilibrium price of Blob will increase, up to twice the original amount
In Scenario 2, the aggregation strategy is not necessarily superior to individual posting
Scenario 3:Both Rollup i and Rollup j Use Calldata as Data Availability Solution
In Scenario 3, the aggregation strategy is not necessarily superior to individual posting
Blob Cost Sharing Mechanisms
Scenario 1 is probably the most realistic scenario, and the following derivation will focus on Scenario 1. Additionally, since Scenario 2 and Scenario 3 don't necessarily adopt an aggregation strategy due to too many variables (like values of P, b), it's difficult to discern some sharing properties.
Property 1: An Optimal Cost Sharing Scheme Always Exists
Property 2: Large Rollups Pay Less Than Their Proportional Transaction Share of Blob Costs
Property 3: Large Rollups Pay More Than Half of the Blob Costs
Property 4: Small Rollups Achieve Greater Cost Reduction Per Transaction
💡 This property is quite intuitive. The aggregation strategy significantly lowers the delay cost for small Rollups, much more than for large Rollups, whose delay cost might not have been high to begin with.
Final Thoughts
The data availability strategies for Rollups introduced by EIP-4844 prompt us to consider both new and established technologies from a more nuanced perspective. Each technology has its applicable scope, and we need to clearly define the utility boundaries of each technology, thus enabling us to use technology more efficiently. The concept of delay cost essentially dominated the derivations in this post, although it often remains unseen in regular discussions.
There remains a vast open field for further research, such as how Rollup data availability strategies might change following the finalization of EIP that limits Calldata. You are welcome to join our discussion and research at ETHconomics Research Space.